About Parallel Bit Reversal
Bit reversal hardware generator:
Please contact me if you need designs for other parameter sets: renchen AT usc.edu.
In this project, we develop novel parallel circuit designs for calculating the bit reversal. To perform bit reversal on 2^n data words, the designs take 2^k (k < n) words as input each cycle. The circuits consist of concatenated single-port buffers and 2-to-1 multiplexers and use minimum number of registers for control. The designs consume minimum number of single-port memory banks that are necessary for calculating continuous-flow bit reversal, as well as near optimal 2^n memory words. The proposed parallel circuits can be built for any given fixed k and n, and achieve superior performance over state-of-the-art for calculating the bit reversal in parallel multi-path FFT architectures.
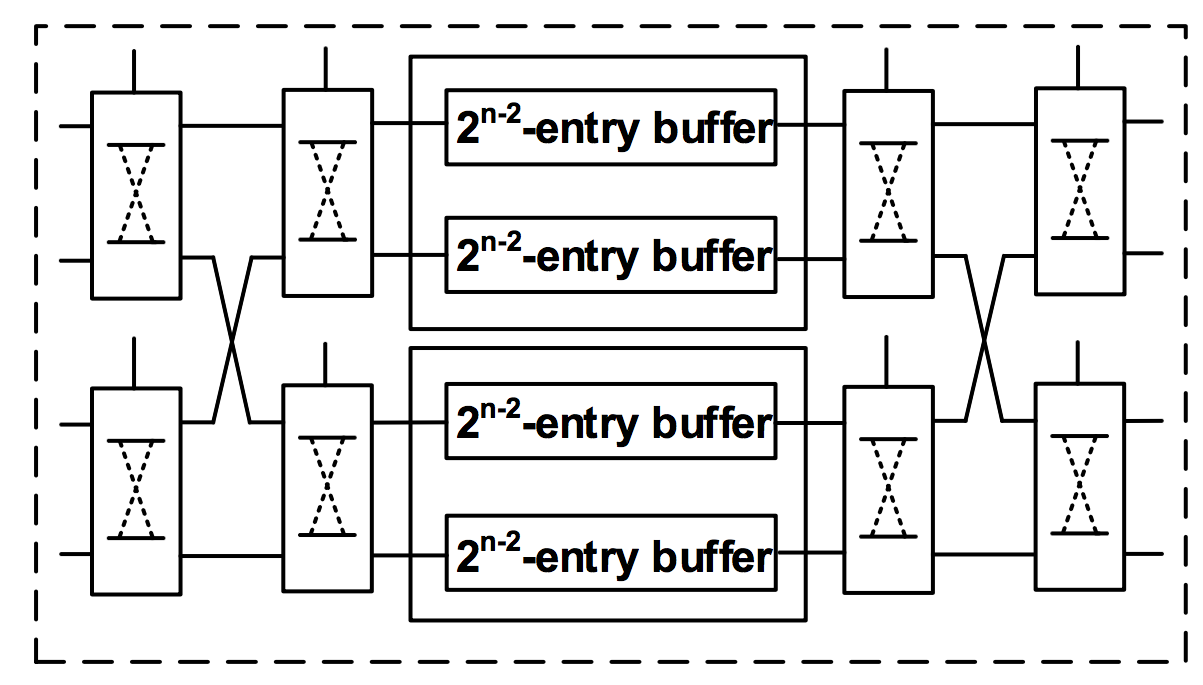
The top left figure shows our parallel design for bit reversal when the data parallelism is 4.
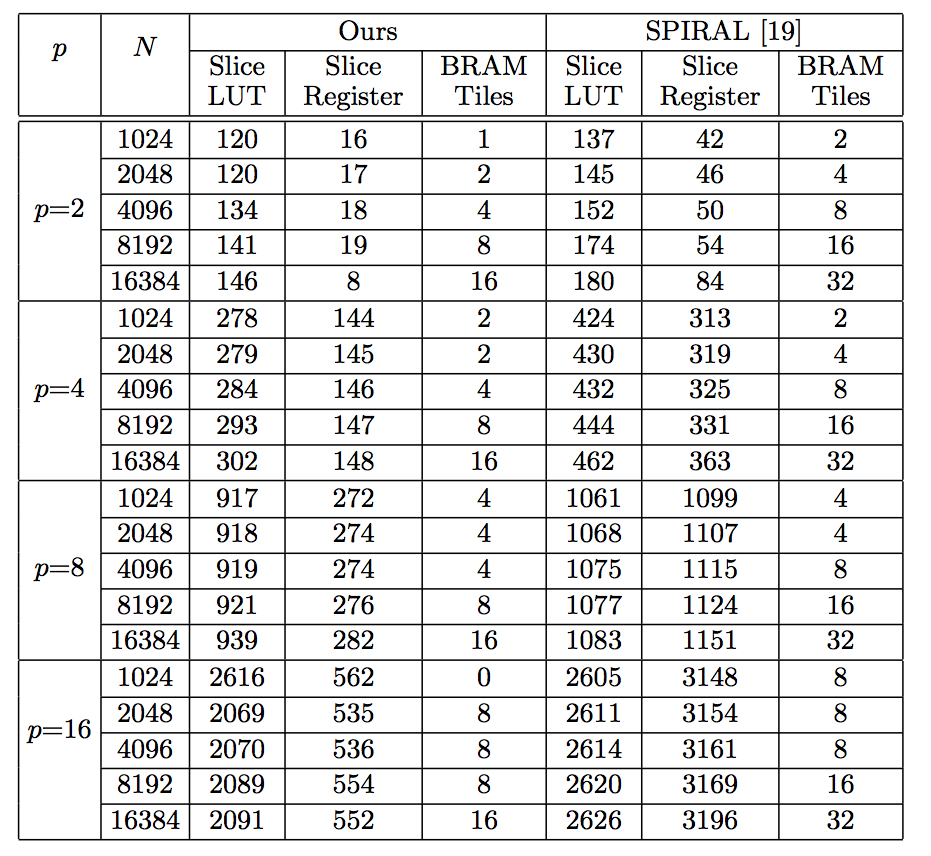
The bottom left figure shows the resource consumption comparison between our design and the design by SPIRAL used in their FFT implementations. p denotes the data parallelism and N is the problem size. The experimental platform is Xilinx Virtex 7.
More technical details can be found in our DAC 2017 paper:
About Sorting
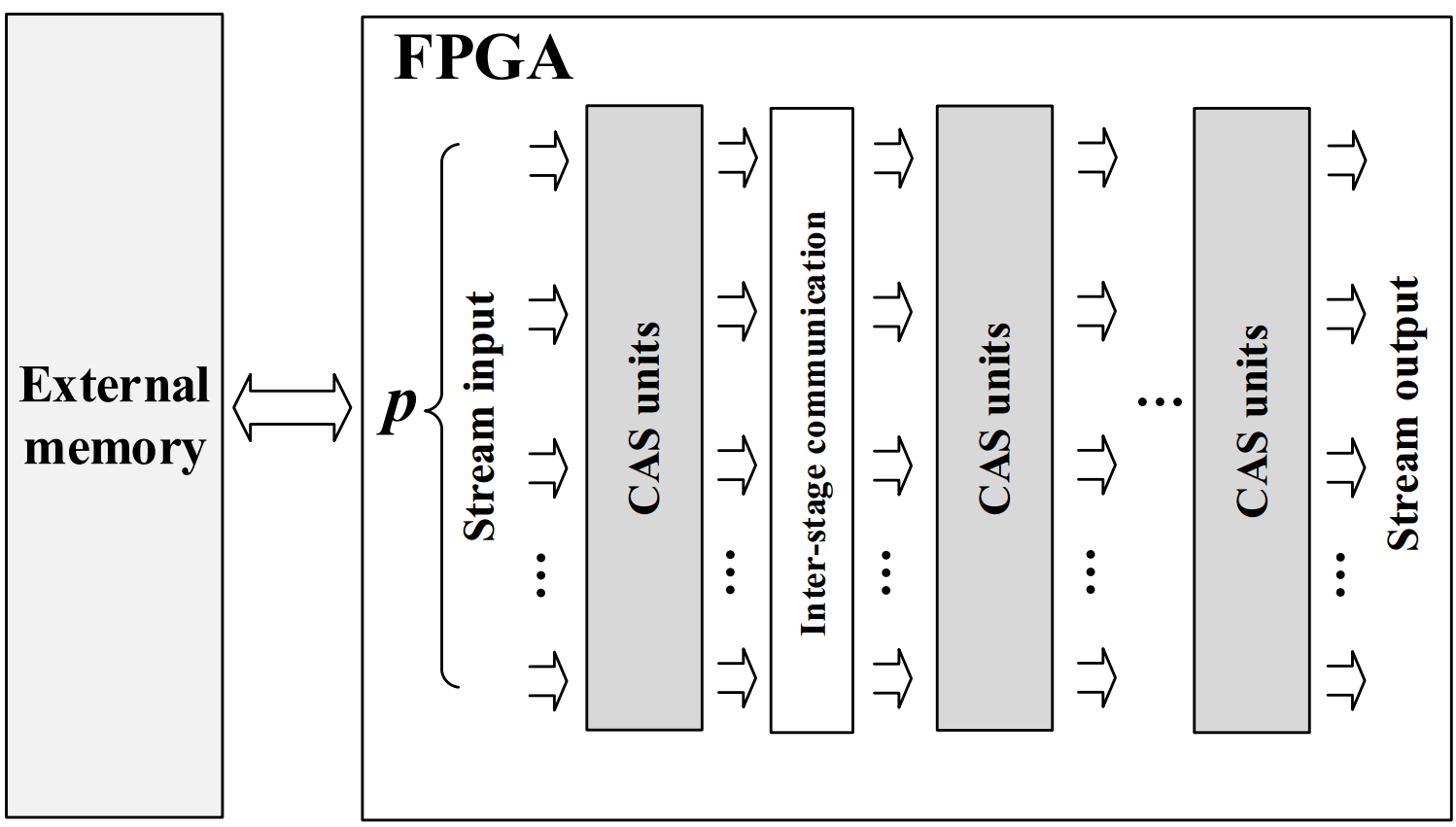
Parallel sorting networks are widely employed in hardware implementations for sorting due to their high data parallelism and low control overhead. We propose an energy and memory efficient mapping methodology for implementing bitonic sorting network on FPGA. Using this methodology, the proposed sorting architecture can be built for any given data parallelism and supports processing continuous data streams. With a data parallelism of p, this design sorts an N-key sequence with a latency of ~6N/p, a throughput (# of keys sorted per cycle) of p and uses ~6N memory. This achieves optimal memory efficiency (defined as the ratio of throughput to the amount of on-chip memory used by the design) compared with the state-of-the-art.
More technical details can be found in our FPGA 2015 paper:About Permutation and Interconnection
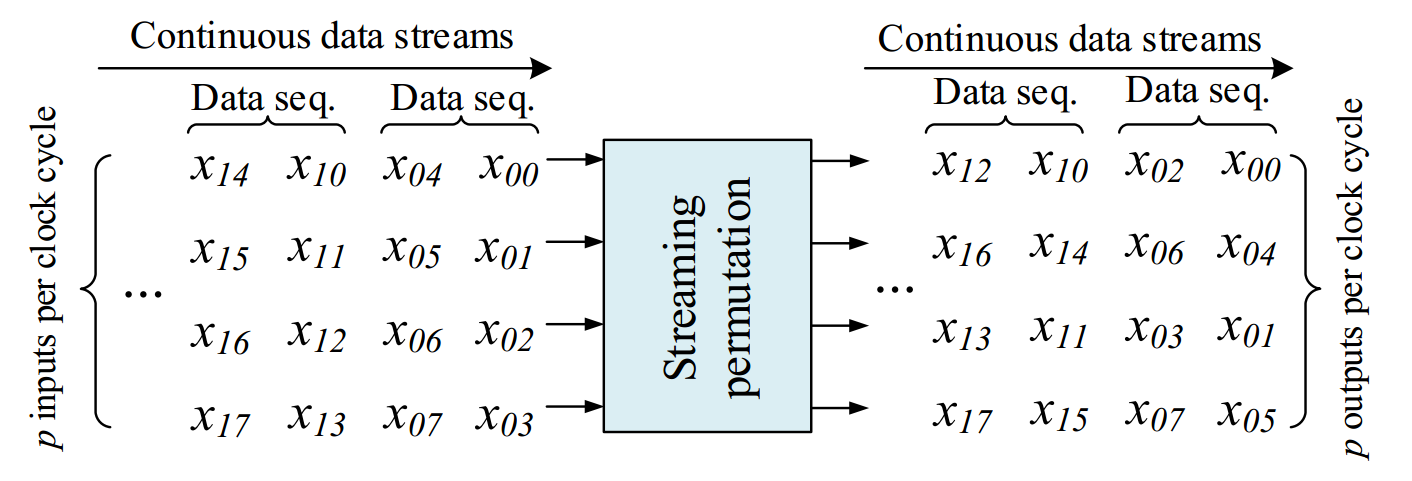
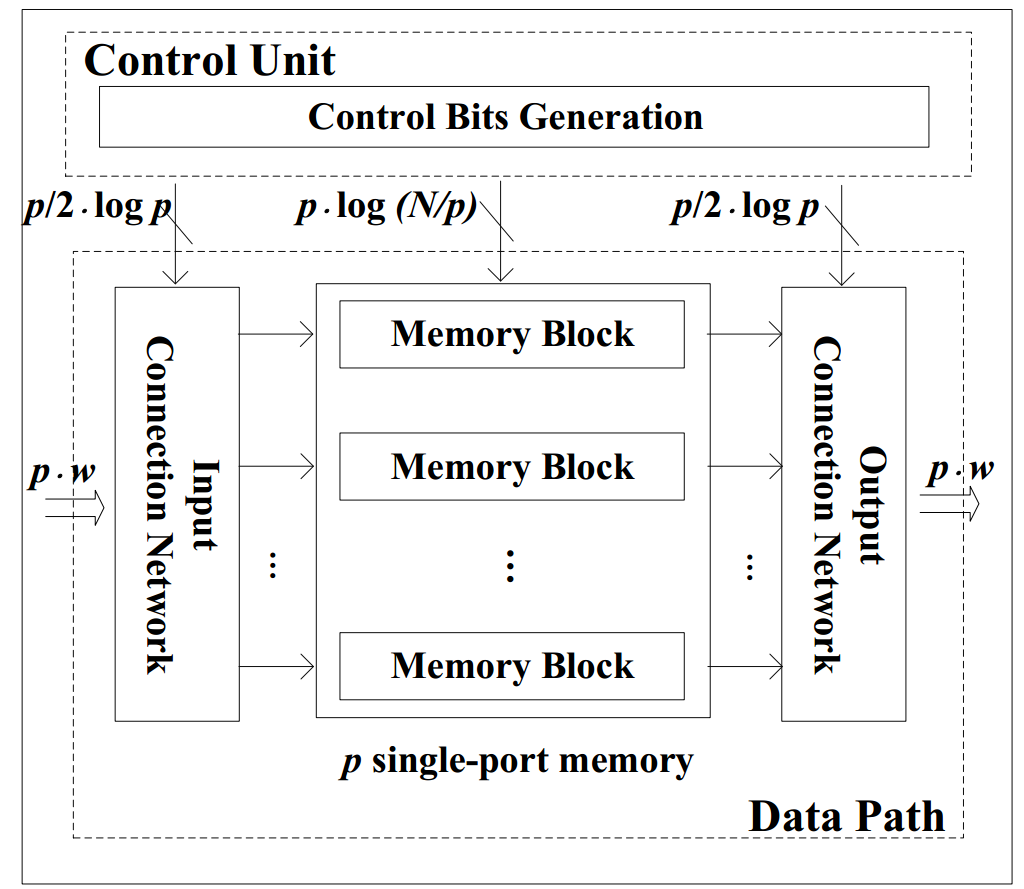
Permutation networks widely exist in various applications including digital signal processing, cryptography and network processing. The interconnection complexity increases dramatically for permuting large data sets. For large data sets, a feasible solution is to build a hardware structure with a fixed data parallelism to permute the input streaming data. Therefore, we develop a novel design for such permutation networks by vertically "folding" the classic Clos network to realize a RAM-based Streaming Permutation Network (RAM-SPN). We prove that the proposed RAM-SPN maintains the rearrangebly non-blocking characteristic of the Clos network and is run-time reconfigurable to realize arbitrary permutations on streaming data. With a data parallelism of p, RAM-SPN permutes an N-element data sequence with latency N/p, throughput (# of data elements permuted per cycle) p and uses N memory. While sustaining the same throughput, our proposed RAM-SPN consumes 4x less memory resource compared with the state-of-the-art.
More technical details can be found in our FPL 2016 paper:About FFT

In this project, we revisit the classic Fast Fourier Transform (FFT) for energy efficient designs on FPGAs. A parameterized FFT architecture is proposed to identify the design trade-offs in achieving energy efficiency. We first perform design space exploration by varying the algorithm mapping parameters, such as the degree of vertical and horizontal parallelism, that characterize decomposition based FFT algorithms. Then we explore an energy efficient design by empirical selection on the values of the chosen architecture parameters, including the type of memory elements, the type of interconnection network and the number of pipeline stages. The trade offs between energy, area, and time are analyzed using two performance metrics: the energy efficiency (defined as the number of operations per Joule) and the Energy x Area x Time (EAT) composite metric. From the experimental results, a design space is generated to demonstrate the effect of these parameters on the various performance metrics. For N-point FFT (16~1024), our designs achieve up to 28% and 38% improvement in the energy efficiency and EAT, respectively, compared with the state-of-the-art design.
About Coarse-grained reconfigurable array
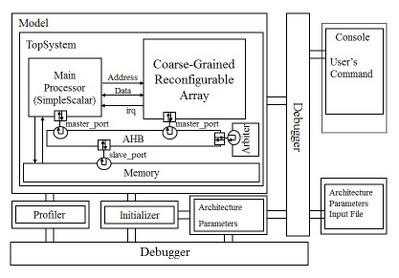
This project is a cycle-accurate reconfigurable system simulator based on the SimpleScalar simulator. The simulator is written in SystemC. As shown in the figure, the simulator core is composed of four parts: Main Processor (SimpleScalar), Coarse-Grained Reconfigurable Array, Memory Module, AHB Bus. Besides, to provides a friendly interface for users to debug, we also add several other modules: profiler, initializer, architecture parameter configuration, debugger, etc.
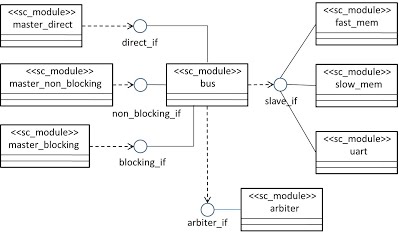
As is shown in the second figure, transaction modeling method in SystemC is adopted in this project for high level simulation.
By transaction level modeling, we implemented the behavioral model of the bus and memory with interface method call, which greatly improved the expandability of the simulator.